
Data Cleaning in Tableau
- Ammu Fredy

- Nov 11, 2022
- 4 min read
After gathering the data for visualization in tableau our next step is to clean the data. For quality decision-making, we need to make sure the data we are using for our analysis is not corrupted, incomplete and without duplicates .so for this, we do Data Cleaning.
What is Data Cleaning?

Image:Photo by PAN XIAOZHEN on Unsplash
Data Cleaning is the process of removing or another way we can say it as fixing our dataset from duplicate and corrupted data . It is one of the most important steps for your organization if you want to create a culture around quality data decision-making.
Tableau has another tool Data Prep that is entirely for cleaning, and transformation .But in this blog, I am gonna discuss the steps for Data Cleaning using Tableau Public Edition.
So let's start now , for my explanations I have created some datasets in Excel. The first step is,to add the data source file to Tableau Workbook . On the left side we can see the Data Interpreter option will appear, which is automatically provided by tableau for the initial level of cleaning of our dataset if it detects empty cells and so on. We can consider it as the first step of Data cleaning.
1. Using Data Interpreter:
The first level of cleaning can be done using the Data Interpreter, Data Interpreter can give you a head start when cleaning a dataset. It can detect titles, notes, footers, empty cells, and so on and bypass them to identify actual fields and values in our dataset, but this method is not much preferred in the actual scenario, because we need to see the null values and need to replace them depending on the dataset

2. Hide columns:
There will be many unwanted columns, we don’t need for our evaluation. So we can hide those columns. We are not actually deleting the columns, but we are instead filtering them out from the workbook file.
If you need to "unhide" the columns later down the road, then all you need to do is return to the Data Source page, and click on the checkbox for Show hidden fields. You should see the hidden columns grayed out, but visible. Then, you can click on the drop-down arrow for the column and select Unhide.

3.Set data type

In this you can clearly see that, price is considered as a string. So the comma is also considered a string.so I need to change it to a number , for that

For that click on ‘Abc’ >>number(decimal).then the price datatype will be changed to number
4. Replace string values
In another scenario where field has some character we want to replace ,we can use replace function for it .In my dataset let's again take the price field it's datatype is kept as string ,so the comma will be also considered in it as string character .So if we want to replace the comma or any string character from the columns.
a.Create a calculated field
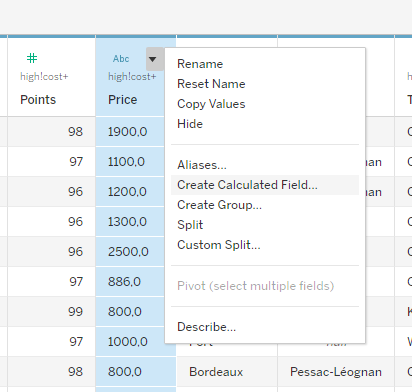
b. We can use replace function to convert the string character ‘,’ to ‘.’


5.Using filter

In this table , you can see that the Sales Amount has a -1 value. In an actual scenario, never a sales amount will be -1 .so it is an error value, we need to clean this value using a filter

a. Go to data>>edit Data Source Filter>>add

b.From the list choose sales amount>>filter window will be opened

c. In that change the min value of range to 1

d. So that sales amount with a -1 value is filtered out

6. Conversion using a calculated field
In the currency column, I can see two USD. In the real case , people have the option to pay in USD too. But for my analysis, I want to change everything to INR.
So click on column on sale amount>>create calculated field>>give a name ‘saleamount change'>>give the below code

So now the sales amount with USD currency will be changed to INR rate .so we can analyze easier with the values.

7. Handle Missing Data:
You may end up with missing values in your data due to errors during data collection or non - responses from respondents. You can avoid this by adding data validation to your survey.
There are 2 common ways of handling missing data, which are; entirely removing the observations from the data set and imputing a new value based on other observations.
a. Drop Missing Values
By dropping missing values, you drop information that may assist you in making better conclusions on the subject of study. It may deny you the opportunity of benefiting from the possible insights that can be gotten from the fact that a particular value is missing.
b.Input Missing Values
So depending on the scenario, we can add values. In case it is an employee survey , if we got non-responsive feedback from employees and some fields that need to be filled with 'yes'/'no' are missing.
Depending on the question, we can put the missing value as ‘no ‘.This will all depend on the dataset. False conclusions because of incorrect or “dirty” data can inform poor business strategy and decision-making.
After the end of the data cleaning process, we should be able to answer the questions as part of validation.
Does your data make sense? If we end up with false conclusion data, it will affect the poor business strategy and business decisions. So it is very important to have good data cleaning. Because data cleaning allows for accurate, defensible data that generates reliable visualization, models, and business decisions.

Comments